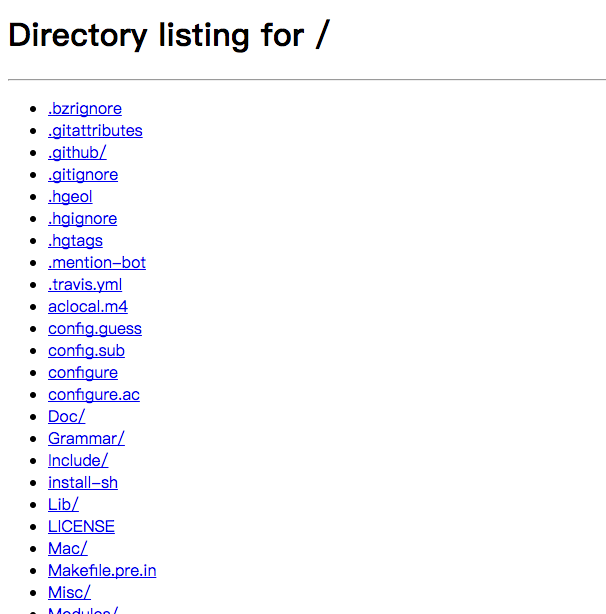
defparse_args(): global host_url global folder_path global verbose # parse our args parser = OptionParser(usage="usage: %prog [options] url") parser.add_option("-v", "--verbose", action="store_true", dest="verbose", help="output process in the console") parser.add_option("-q", "--quiet", action="store_false", dest="verbose", default=False, help="disable the output in the console[default]") parser.add_option("-f", "--folder", metavar="FOLDER", default='folder/', help="the path to store the download content"), (options, args) = parser.parse_args() iflen(args) == 0: parser.error("incorrect number of arguments") host_url = args[0] folder_path = options.folder verbose = options.verbose
defdeal_arg(): # to parse host url global host_url global folder_path url_match = r'^((ht|f)tps?):\/\/[\w\-]+(\.[\w\-]+)+([\w\-\.,@?^=%&\/:~\+#]*[\w\-\@?^=%&\/~\+#])?$' ifnot re.match(url_match, host_url): seconnd_match = r'^[\w\-]+(\.[\w\-]+)+([\w\-\.,@?^=%&\/:~\+#]*[\w\-\@?^=%&\/~\+#])?$' if re.match(seconnd_match, host_url): host_url = 'http://' + host_url else: raise(ValueError("url invalid. Check it again.")) if host_url[-1] != '/': host_url += '/' print("You're get the folder under the url: " + host_url)
# to parse the folder if folder_path[-1] != '/': folder_path += '/' ifnot os.path.exists(folder_path): os.mkdir(folder_path) os.chdir(folder_path)